監督式學習是機器學習的一種,透過有標記正確答案的資料建立模型進而去預測未知答案的結果。針對不同的情境和輸出結果可以分為:
回歸問題 (Regression):
分類問題 (Classification):
這裡沒有將模型再歸類為回歸模型或分類模型是因為一個模型隨著不同的情境還有預測結果的改變不全然只局限於一種用途。在開發或使用模型上最重要的是如何定義問題。
俗話說:「女人心,海底針」,鄉民們稱那些不懂女生心思、反應遲鈍、不貼心、很木頭的男生為「直男」。今天為了擺脫這個負面標籤,我希望透過一些特徵 (features) 來預測女朋友的情緒反應。這類型的題目就是分類問題,它的目標變量 (target variable) 可能是開心或生氣。在這個案例中,我們選擇「決策樹」作為我們的分類模型並進行訓練和預測。
程式碼如下:
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.tree import export_graphviz
import graphviz
import numpy as np
# 生成假資料
np.random.seed(0)
data = {
'sleep_hours': np.random.randint(2, 9, 10),
'work_stress_level': np.random.randint(1, 6, 10),
'said_goodnight': np.random.randint(0, 2, 10), # 0:沒說晚安, 1:有說晚安
'mood': np.random.choice(['happy', 'angry'], 10)
}
df = pd.DataFrame(data)
# 特徵欄位和目標變量
X = df[['sleep_hours', 'work_stress_level', 'said_goodnight']]
y = df['mood']
# 將標籤轉換為數值
y = y.map({'happy': 0, 'angry': 1})
# 將資料切割成訓練集 (training set) 跟測試集 (test set)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
# 建立 Decision Tree 模型
clf = DecisionTreeClassifier()
clf.fit(X_train, y_train)
# 預測
y_pred = clf.predict(X_test)
# 評估模型
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy}')
# 建立新數據並進行預測
new_data = pd.DataFrame({
'sleep_hours': [7],
'work_stress_level': [2],
'said_goodnight': [1]
})
prediction = clf.predict(new_data)
print(f'Prediction for new data: {"happy" if prediction[0] == 1 else "angry"}')
# 畫出決策圖
dot_data = export_graphviz(clf, out_file=None,
feature_names=['sleep_hours', 'work_stress_level', 'said_goodnight'],
class_names=['angry', 'happy'],
filled=True, rounded=True,
special_characters=True)
graph = graphviz.Source(dot_data)
graph
1. 資料生成
np.random.seed(0)
data = {
'sleep_hours': np.random.randint(2, 9, 10),
'work_stress_level': np.random.randint(1, 6, 10),
'said_goodnight': np.random.randint(0, 2, 10), # 0: 沒說晚安, 1: 有說晚安
'mood': np.random.choice(['happy', 'angry'], 10)
}
df = pd.DataFrame(data)
np.random.seed() 確保每次生成的資料是一樣的(想像成將這個隨機生成的資料貼一個標籤)。np.random.randint() 用來隨機生成整數型態的資料。np.random.choice() 用來隨機生成指定列表 (list) 裡面的資料。2. 特徵工程 (feature engineering)
X = df[['sleep_hours', 'work_stress_level', 'said_goodnight']]
y = df['mood']
y = y.map({'happy': 0, 'angry': 1})
sleep_hours、work_stress_level、said_goodnight 作為判斷目標變量 mood 的 features。mood 欄位從類別型資料轉換成數值型資料。3. 資料分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
random_state 確保每次生成的訓練集和測試集是一樣的。4. 模型訓練與評估
clf = DecisionTreeClassifier()
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy}')
5. 產生新數據並進行預測
new_data = pd.DataFrame({
'sleep_hours': [7],
'work_stress_level': [2],
'said_goodnight': [1]
})
prediction = clf.predict(new_data)
print(f'Prediction for new data: {"happy" if prediction[0] == 1 else "angry"}')
6. 決策樹視覺化
dot_data = export_graphviz(clf, out_file=None,
feature_names=['sleep_hours', 'work_stress_level', 'said_goodnight'],
class_names=['angry', 'happy'],
filled=True, rounded=True,
special_characters=True)
graph = graphviz.Source(dot_data)
graph
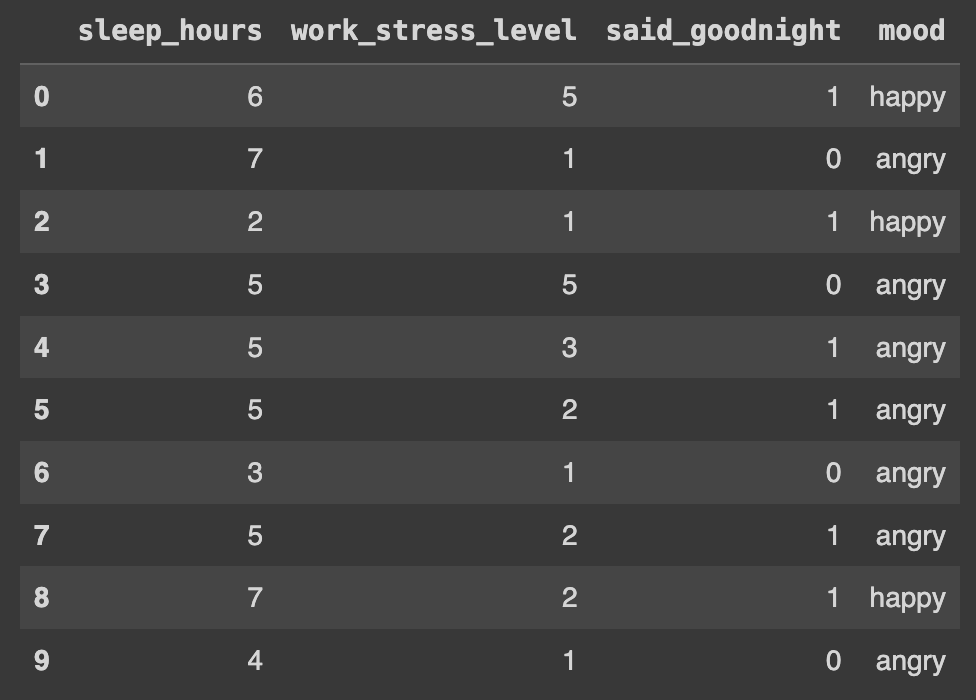
export_graphviz() 將決策樹導出成 Graphviz 格式。graphviz.Source() 進行視覺化呈現。建立的假資料如下:
決策圖如下:
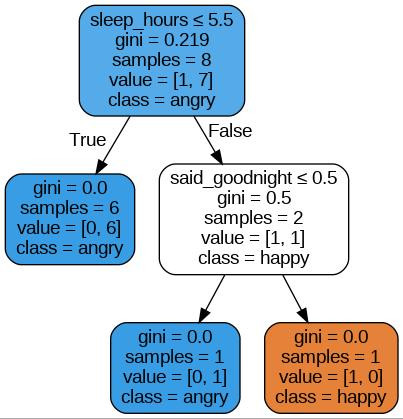
透過這棵決策樹我們可以進行情緒預測:
因為這個資料集是隨機生成的,所以可以發現這個決策樹結果跟我們所認知的常理可能不太一樣(睡越飽應該越不容易 angry 才對?)。如果想要讓這個研究更加實用,可以開始每天記錄女朋友的習性,透過真實資料訓練出來的模型相信一定比這個隨機生成的模型優秀個 100 倍。
後續在處理任何問題也都會以這樣的模式先定義問題,思考解決方法,最後進行實驗 和驗證。
我作為十年的 KD 粉雖然沒能夠親眼見證 KD 加冕成為美國隊史得分王(看加拿大 vs 法國到第三節開始就昏睡了哈哈),但必須得說在我心中他毫無疑問是美國男籃的 GOAT 🐐。今年奧運第一場就讓我們見識到為什麼他外號叫 Easy Money,全場 9 投 8 中高效率砍下 23 分,當下我真的看傻了但真的很爽。這次奧運也是詹庫杜的國際賽最後一舞,佔據我大半青春的未來名人堂成員也快退役了😭。

